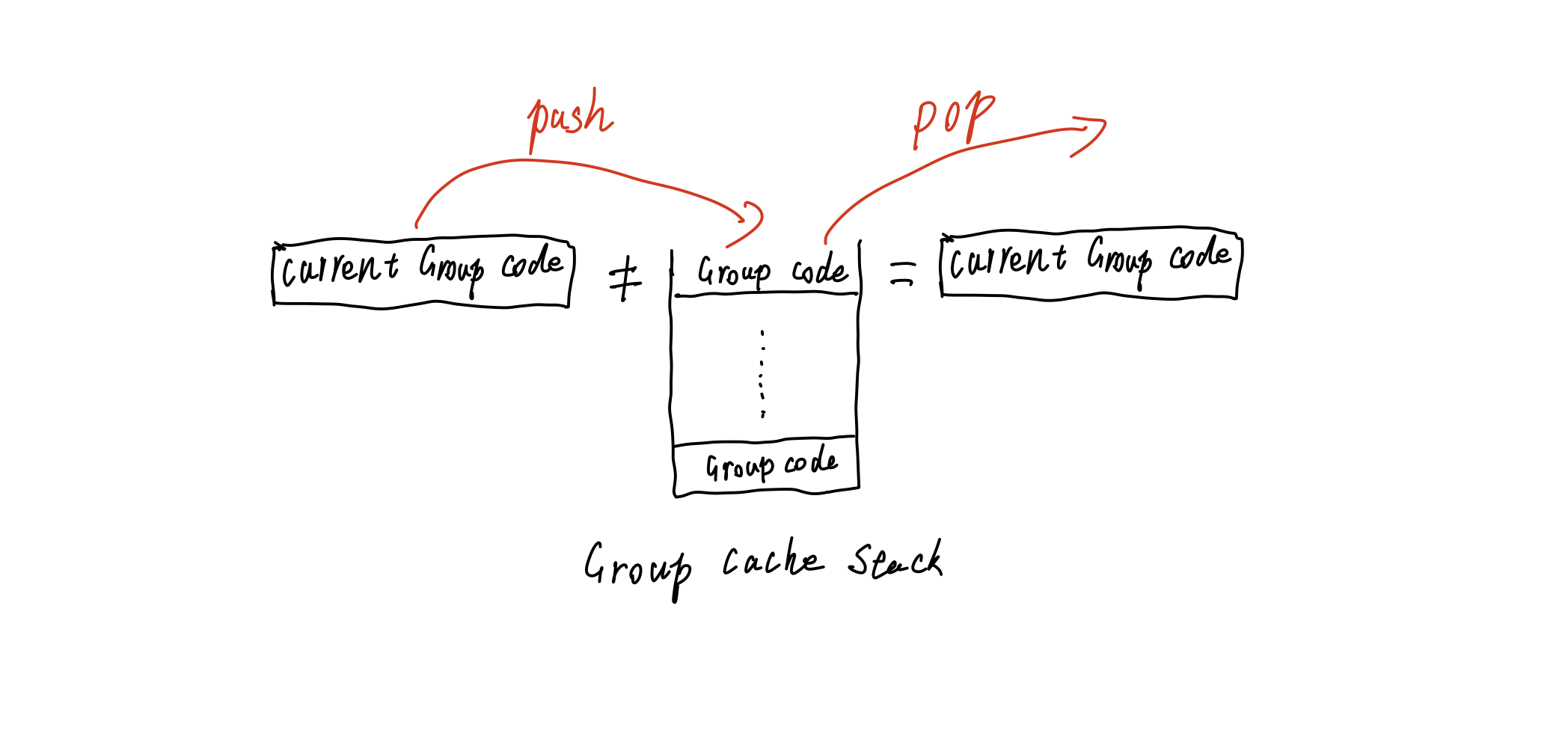
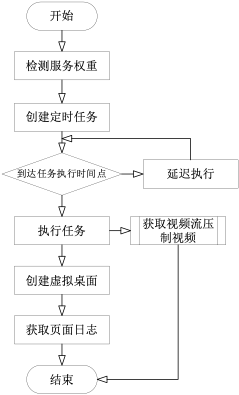
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
| import * as process from 'child_process';
class XvfbMap {
private xvfb: {
[key: string]: {
process: process.ChildProcessWithoutNullStreams;
display: number;
execPath?: string;
};
} = {};
setXvfb = (key: string, display: number, process: process.ChildProcessWithoutNullStreams, execPath?: string) => {
this.xvfb[key] = {
display,
process,
execPath,
};
};
getSpecXvfb = (key: string) => {
return this.xvfb[key];
};
getXvfb = () => this.xvfb;
}
const xvfbIns = new XvfbMap();
const checkoutDisplay = (num: number, execPath?: string) => {
const path = execPath || '/dev/null';
return new Promise<boolean>((res, rej) => {
const xdpyinfo = process.spawn('xdpyinfo', [
'-display',
`:${num}>${path}`,
'2>&1',
'&&',
'echo',
'inUse',
'||',
'echo',
'free',
]);
xdpyinfo.stdout.on('data', (data) => res(data.toString() === 'inUse'));
xdpyinfo.stderr.on('data', (data) => rej(data.toString()));
});
};
const getRunnableNumber = async (execPath?: string): Promise<number> => {
const num = Math.floor(62396 * Math.random());
const isValid = await checkoutDisplay(num, execPath);
if (isValid) {
return num;
} else {
return getRunnableNumber(execPath);
}
};
export const xvfbStart = async (
key: string,
option: { width: number; height: number; depth: 15 | 16 | 24 },
execPath?: string
) => {
const randomNum = Math.floor(62396 * Math.random());
const { width, height, depth } = option;
try {
const xvfb = process.spawn('Xvfb', [
`:${randomNum}`,
'-screen',
'0',
`${width}x${height}x${depth}`,
'-ac',
'-noreset',
]);
xvfbIns.setXvfb(key, randomNum, xvfb, execPath);
return randomNum;
} catch (error) {
console.log(error);
return 99;
}
};
export const xvfbStop = (key: string) => {
const xvfb = xvfbIns.getSpecXvfb(key);
return xvfb.process.kill();
};
export default xvfbIns;
|