通过改变列表项位置更新分组关系#

要解决的问题#
- 移动分组时,分组所有的子项都要移动,且保持相对位置和关系不变
- 批量移动未分组列表项到分组内时,相对位置应不变
- 已分组列表项移动出分组范围时应,应解除分组关系
分析#
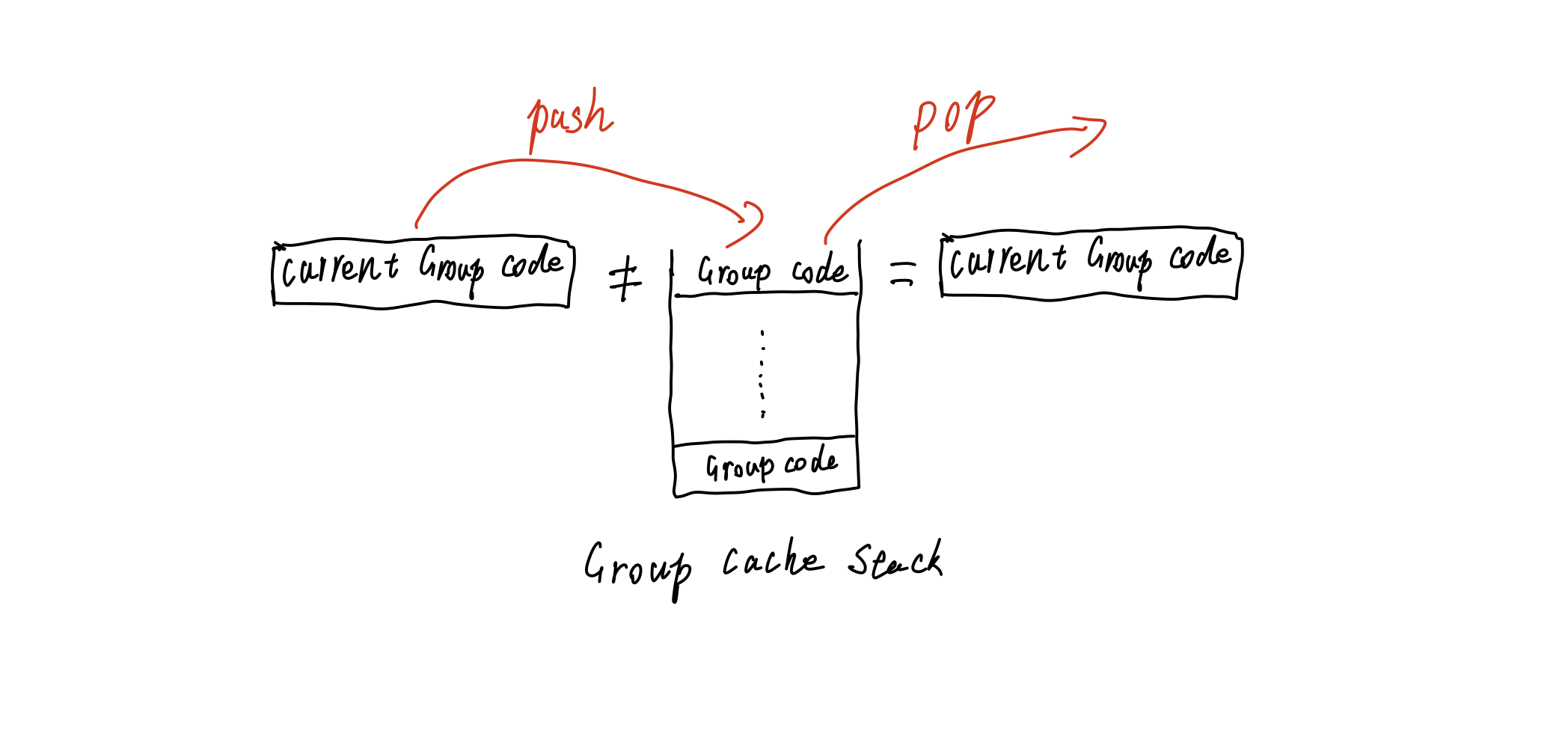
当分组移动时,所有分组的子项都不变,首先需要搜索到分组内所有的子项。然后记录该子项在分组内的相对位置,以及在整体列表中的位置。 这样在移动时,方便进行计算。
整体来讲,这个移动过程中的搜索部分将使用深度优先搜索的一种变种。移动后的排序,只需遵守搜索中分组和其子项的相对顺序遍历即可。
分组子项搜索流程如下: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17if (!groupCache.includes(hasGroup)) {
//组件的分组不在查询的分组内。弹出所有的分组缓存
groupCache = [];
return;
} else {
result.push(item); //组件的分组在分组缓存中
if (hasGroup !== groupCache[groupCache.length - 1]) {
// 如果组件的分组不在缓存的顶层
const hasGroupCacheIndex = groupCache.indexOf(hasGroup);
groupCache = groupCache.slice(0, hasGroupCacheIndex + 1);
}
if (compDatas[item].compCode === 'group') {
// 组件本身是分组组件
groupCache.push(item);
}
}
列表项排序流程如下: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
/**
* compDatas 所有的列表项{[code]:{ config: { [groupCode]:groupCode } } }
* topLestSelectComps 和第一个要移动的列表项在同级的组件(处理批量移动的情况),数据结构与compDatas一致
* nearLowBoundsGroup 将要移动列表项所在的分组的下界,数据结构与compDatas一致
*/
if (isToplest) {
//如果移动位置在插入区间的顶部,表明组件在最外层
topLestSelectComps.forEach((item) => {
result[item] = { newGroup: undefined, oldGroup: compDatas[item].config.groupCode };
return (compDatas[item].config.groupCode = undefined);
});
return result;
}
if (nearLowBoundsGroup !== firstCompPrev) {
//如果移动位置的下界的分组code不等于移动组件的code,则解除或更新分组关系
topLestSelectComps.forEach((item) => {
if (item !== nearLowBoundsGroup) {
result[item] = { newGroup: nearLowBoundsGroup, oldGroup: compDatas[item].config.groupCode };
compDatas[item].config.groupCode = nearLowBoundsGroup;
} else {
result[item] = { newGroup: compDatas[item].config.groupCode, oldGroup: compDatas[item].config.groupCode };
}
});
return result;
}
return result;
};
实现#
分组子项查询详细代码
interface GroupConfigStruct {
groupItemCode: string[];
}
interface groupMapValueStruct {
//分组内组件相对于分组索引的偏移量
offsetNumer: number;
//分组的索引
currentIndex: number;
}
/**
*根据分组关系排序一维数组
*@param compCodes 所有组件的code
*@param compDatas 所有组件的数据
*/
const sortListItem = (compCodes: string[], compDatas: JDV.State['compDatas']) => {
const groupCodeCache = new Map();
const result: string[] = [];
/**
*递归的回溯当前分组的前驱分组,更新前驱分组的长度偏移量
*@param groupCode 分组组件的code
*@param offsetNumber 分组长度的偏移量
*/
const recursiveBacktracking = (groupCode: string, offsetNumber: number): null => {
const parentGroupCode = compDatas[groupCode].config.groupCode;
const belongGroup = groupCodeCache.get(groupCode) as groupMapValueStruct;
groupCodeCache.set(groupCode, {
//更新分组缓存,每此插入组件,偏移量+1
...belongGroup,
offsetNumer: belongGroup.offsetNumer + 1,
});
if (parentGroupCode) {
// 如果分组有父分组,回溯一步
return recursiveBacktracking(parentGroupCode, offsetNumber + 1);
} else {
return null;
}
};
compCodes.forEach((item, index) => {
const group = compDatas[item].config.groupCode ? compDatas[item].config.groupCode : null;
if (compDatas[item].compCode === 'group') {
//如果组件是分组组件,将code推入分组缓冲内
groupCodeCache.set(item, { offsetNumer: 0, currentIndex: index });
}
if (group) {
//在分组内
if (groupCodeCache.has(group)) {
// 组件的分组在缓存中
const belongGroup = groupCodeCache.get(group) as groupMapValueStruct;
// 分组内组件插入的位置
const targetIndex = belongGroup.currentIndex + belongGroup.offsetNumer;
result.splice(targetIndex + 1, 0, item);
recursiveBacktracking(group, belongGroup.offsetNumer);
}
} else {
result.push(item);
}
});
return result;
};
export default sortListItem;
分组移动后排序详细代码
/**
* 组件排序时处理分组的逻辑。
* @param compCodes 所有组件的code
* @param compDatas 所有组件的数据
* @param code 当前组件code
* @param destination 目标位置
* @returns result {Result} 返回组件排序后的分组关系,用于分组关系变化后,处理分组的尺寸。
*/
export const groupResort = (
compCodes: string[],
selectedCompCodes: string[],
compDatas: JDV.State['compDatas'],
destination: number
): Result => {
const isToplest = destination === 0;
const isBottomlest = destination + 1 === compCodes.length - 1;
const lowBounds = isBottomlest ? compCodes.length - 1 : destination + 1;
const interval = compCodes.slice(0, lowBounds); //插入区间
const intervalLastComp = compDatas[compCodes[lowBounds]];
const nearLowBoundsGroup = interval.find((item) => intervalLastComp && item === intervalLastComp.config.groupCode); //插入区间最下面的分组段
const firstCompPrev = compDatas[selectedCompCodes[0]] && compDatas[selectedCompCodes[0]].config.groupCode; // 第一个选中组件的分组
const topLestSelectComps = selectedCompCodes.filter((item) => compDatas[item].config.groupCode === firstCompPrev); // 和第一个选中在同级的所有选中组件
const result: Result = {};
if (isToplest) {
//如果移动位置在插入区间的顶部,表明组件在最外层
topLestSelectComps.forEach((item) => {
result[item] = { newGroup: undefined, oldGroup: compDatas[item].config.groupCode };
return (compDatas[item].config.groupCode = undefined);
});
return result;
}
if (nearLowBoundsGroup !== firstCompPrev) {
//如果移动位置的下界的分组code不等于移动组件的code,则解除或更新分组关系
topLestSelectComps.forEach((item) => {
if (item !== nearLowBoundsGroup) {
result[item] = { newGroup: nearLowBoundsGroup, oldGroup: compDatas[item].config.groupCode };
compDatas[item].config.groupCode = nearLowBoundsGroup;
} else {
result[item] = { newGroup: compDatas[item].config.groupCode, oldGroup: compDatas[item].config.groupCode };
}
});
return result;
}
return result;
};