Recording web pages to video at a specified time through a server
- Why is there such a need?
- My goal
- Choice of technology stack
- The specific implementation
- Q & A
- Project address
Why is there such a need?#
I recently work in the field of front-end data visualization, and the need for some monitoring of long-running front-end pages comes up. In the past, my solution was to record through some existing platform on my personal PC via browser, or an earlier approach was to record through some screen recording tools.
In such an approach, the following problems were often encountered.
- Insufficient resolution to restore
- The recorded log format is difficult to parse
- Need to open the personal computer for a long time
- ** What is recorded through the platform is often not a video, but a DOM-Mirror recording. Such logs are difficult to share with others for troubleshooting**
- DOM-Mirror recordings for playback lack value for rendering real-time data returned by the backend (because the point in time has been missed, and playback cannot play back the service state of the backend at that time)
- The number of concurrent recordings is limited by the performance of personal computers
- Recorded files are not well managed
My goal#
So, based on the above needs, we need to achieve the following requirements.
- Record at the native resolution required by the web page
- Be able to record on the server side and not on the PC
- The ability to record generic video and log files that can be easily shared with others
- Ability to make concurrent recordings
- Video frame rate should be smooth enough (at least at 4K)
- Provide access to static resources for recorded files
Choice of technology stack#
- Base language and framework - js & nodejs
- For running tasks at specified times -- cron job
- For opening web pages -- puppeteer
- For video recording the following options are available
- Use the browser api
getDisplayMediafor recording - Use puppeteer to take a screenshot by frame, then compress the image with ffmpeg
- Use xvfb to record the video stream from the virtual desktop directly by encoding it with ffmpeg
- Use the browser api
- For recording logs -- puppeteer provides devtools related events
- For concurrent processing -- introduce weighted calculations
- For video processing -- ffmpeg
The specific implementation#
I. Current solution#
The main problems that this solution circumvents to solve are.#
- The use of
getDisplayMediais limited by the browser's protocol. This api is only available when the access protocol is https, and the recording of audio depends on other api. - The performance of
getDisplayMediahas little room for optimization when recording multiple pages concurrently, and the most fatal problem is that the performance overhead of the recording process is borne by the browser. This means that if the page itself is more performance sensitive, it is basically impossible to record the page running properly using this api. - puppeteer's frame-by-frame screenshots are limited by chrome-devtools itself, resulting in only 10+ images being cut out a second. In a data visualization scenario, a large amount of real-time data rendering is obviously unacceptable as well.
Core Processes#
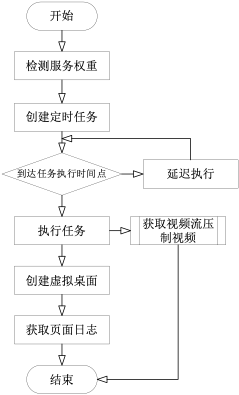
Key points.#
- use node call xvfb, create virtual desktops: open source library
node-xvfbhas some problems, the virtual desktops created, seem to share the same stream buffer, in the case of concurrent recording, there will be a situation of preemption, resulting in accelerated video content, so the need to encapsulate a new node call xvfb
1 | import * as process from 'child_process'; |
Load balancing during concurrent server recording. This feature is to solve the problem of high server CPU load when recording video encoding concurrently. So to maximize the number of concurrent recordings, I record the number of tasks being and will be performed by each server, mark this number as the weight of the service, and when a new recording task is created, first check the weight of the current server, then create the recording task on the server with the lowest weight, and lower the weight when the recording is completed and the task is manually terminated.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33import { CronJob } from 'cron';
interface CacheType {
[key: string]: CronJob;
}
class CronCache {
private cache: CacheType = {};
private cacheCount = 0;
setCache = (key: string, value: CronJob) => {
this.cache[key] = value;
this.cacheCount++;
return;
};
getCache = (key: string) => {
return this.cache[key];
};
deleteCache = (key: string) => {
if (this.cache[key]) {
delete this.cache[key];
}
this.cacheCount = this.cacheCount > 0 ? this.cacheCount - 1 : 0;
};
getCacheCount = () => this.cacheCount;
getCacheMap = () => this.cache;
}
export default new CronCache();When starting puppeteer, you need to provide parameters
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22const browser = await puppeteer.launch({
headless: false,
executablePath: '/usr/bin/google-chrome',
defaultViewport: null,
args: [
'--enable-usermedia-screen-capturing',
'--allow-http-screen-capture',
'--ignore-certificate-errors',
'--enable-experimental-web-platform-features',
'--allow-http-screen-capture',
'--disable-infobars',
'--no-sandbox',
'--disable-setuid-sandbox',//关闭沙箱
'--start-fullscreen',
'--display=:' + display,
'-–disable-dev-shm-usage',
'-–no-first-run', //没有设置首页。
'–-single-process', //单进程运行
'--disable-gpu', //GPU硬件加速
`--window-size=${width},${height}`,//窗口尺寸
],
});
solution performance (in docker)#
- Standard 1k resolution: dual-core CPU 2.3Ghz; 10 concurrent at 4G ram
- Standard 2k resolution: dual-core CPU 2.3Ghz; 4 concurrent under 4G ram
II. Tried and tested solutions#
getDisplayMedia mode#
Key points#
The api call causes chrome to pop up an interactive window to choose which specific web page to record. Closing this window requires the following parameters to be enabled when starting puppeteer
1
2
3
4
5
6
7
8
9'--enable-usermedia-screen-capturing',
`-auto-select-desktop-capture-source=recorder-page`,
'--allow-http-screen-capture',
'--ignore-certificate-errors',
'--enable-experimental-web-platform-features',
'--allow-http-screen-capture',
'--disable-infobars',
'--no-sandbox',
'--disable-setuid-sandbox',To execute the recording, you need to inject the function via puppeteer
page.exposeFunction.
Q & A#
Q: Why do I need to introduce xvfb?
A: In the tried and tested solution, getDisplayMedia requires the runtime environment to provide a desktop environment. In the current solution, it is necessary to push the video stream from xvfb directly into ffmpeg
Q: Why are there certain memory requirements?
A: To provide the minimum running memory for chrome
Project address#
https://github.com/sadofriod/time-recorder
Recording web pages to video at a specified time through a server
http://sadofriod.github.io/Recording-web-pages-to-video-at-a-specified-time-through-a-server.html